Appearance
Golang 基础
下划线
在Golang之中,import用于引入其他package,其作用是当导入一个包时,该包下的文件里所有init()函数都会被执行,然而,有些时候我们并不需要把整个包都导入进来,仅仅是是希望它执行init()函数而已。这个时候就可以使用 import 引用该包。即使用import _ 包路径只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数。
目录数如下:
.
├── go.mod
├── go.sum
├── main.go
└── test
└── test.go
.
├── go.mod
├── go.sum
├── main.go
└── test
└── test.go
// main.go
package main
import _ "test"
func main() {
test.Print() // 编译报错,# code.personal.cc ./main.go:8:2: undefined: test
}
// test.go
package test
import "fmt"
func init() {
fmt.Print("func_init Print()")
}
func Print() {
fmt.Print("func_Print")
}
// main.go
package main
import _ "test"
func main() {
test.Print() // 编译报错,# code.personal.cc ./main.go:8:2: undefined: test
}
// test.go
package test
import "fmt"
func init() {
fmt.Print("func_init Print()")
}
func Print() {
fmt.Print("func_Print")
}
此外还可以:
file,_ := os.Open("/PATH/TO/FILE")
/*
os.Open()函数的返回值为*os.File,error,但有时候我们并不想要error返回值,则使用_占位符将其舍弃掉
*/
file,_ := os.Open("/PATH/TO/FILE")
/*
os.Open()函数的返回值为*os.File,error,但有时候我们并不想要error返回值,则使用_占位符将其舍弃掉
*/
变量和常量
变量
变量声明:
// 基本语法
var <variable_name> <variable_type>
// 批量声明变量
var (
<variable_name1> <variable_type1>
<variable_name1> <variable_type1>
...
)
// 基本语法
var <variable_name> <variable_type>
// 批量声明变量
var (
<variable_name1> <variable_type1>
<variable_name1> <variable_type1>
...
)
变量初始化:
// 基本语法
var <variable_name> <variable_type> = <expression>
// 自动推导变量类型,即可省略<variale_type>
var <variable_name> = <expression/value>
// 基本语法
var <variable_name> <variable_type> = <expression>
// 自动推导变量类型,即可省略<variale_type>
var <variable_name> = <expression/value>
短变量声明赋值:
<variable_name> := <expression/value>
<variable_name> := <expression/value>
匿名变量:
x,_ := foo()
x,_ := foo()
⚠️ 注意:
函数外的每个语句都必须以关键字开始(var、const、func等)
:=不能使用在函数外
_多用于占位,表示忽略值
常量
常量声明并赋值:
const pi = 3.1415
// 同时声明或者赋值多个常量
const (
<variable_name1> = <value1>
<variable_name2>
...
)
const pi = 3.1415
// 同时声明或者赋值多个常量
const (
<variable_name1> = <value1>
<variable_name2>
...
)
iota
iota是golang语言的常量计数器,只能在常量的表达式中使用。iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。使用iota能简化定义,在定义枚举时很有用。
const a = iota
const (
b = iota
c
d = 3.14 // 截断iota
e // 不写则与上一个常量或者表达式相同
f = iota // 继续iota计数
g
)
fmt.Print(a, b, c, d, e, f, g) //输出结果为0 0 1 3.14 3.14 4 5
// 如果想要跳过某值,可以使用`_`占位符进行跳过,如下:
const (
x = iota
_
_
y
)
fmt.Print(x,y) //输出结果为0 3
const a = iota
const (
b = iota
c
d = 3.14 // 截断iota
e // 不写则与上一个常量或者表达式相同
f = iota // 继续iota计数
g
)
fmt.Print(a, b, c, d, e, f, g) //输出结果为0 0 1 3.14 3.14 4 5
// 如果想要跳过某值,可以使用`_`占位符进行跳过,如下:
const (
x = iota
_
_
y
)
fmt.Print(x,y) //输出结果为0 3
定义数量级:
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
数据类型
更多参考:https://www.geeksforgeeks.org/data-types-in-go/
String
赋值多行字符串给变量:
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
字符串处理及函数参考[./String Operate](./String Operate.md)
byte和rune类型
Go 语言的字符有以下两种:
- uint8类型:或者叫 byte 型,代表了ASCII码的一个字符。
- rune类型:代表一个 UTF-8字符,用于处理中文、日文或者其他复合字符
数组
一维数组
package main
import (
"fmt"
)
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
func main() {
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}
fmt.Println(arr0, arr1, arr2, str)
fmt.Println(a, b, c, d)
}
// output
[1 2 3 0 0] [1 2 3 4 5] [1 2 3 4 5 6] [ hello world tom]
[1 2 0] [1 2 3 4] [0 0 100 0 200] [{user1 10} {user2 20}]
package main
import (
"fmt"
)
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
func main() {
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}
fmt.Println(arr0, arr1, arr2, str)
fmt.Println(a, b, c, d)
}
// output
[1 2 3 0 0] [1 2 3 4 5] [1 2 3 4 5 6] [ hello world tom]
[1 2 0] [1 2 3 4] [0 0 100 0 200] [{user1 10} {user2 20}]
二维数组
package main
import (
"fmt"
)
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
func main() {
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。
fmt.Println(arr0, arr1)
fmt.Println(a, b)
}
func bianli() {
var x [2][2]int = [...][2]int{{1, 2}, {3, 4}}
for k1, v1 := range x {
for k2, v2 := range v1 {
fmt.Printf("(%d,%d)=%d", k1, k2, v2)
}
fmt.Println()
}
}
// output
[[0 0 0] [0 0 0] [0 0 0] [0 0 0] [0 0 0]] [[1 2 3] [7 8 9]]
[[1 2 3] [4 5 6]] [[1 1] [2 2] [3 3]]
package main
import (
"fmt"
)
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
func main() {
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。
fmt.Println(arr0, arr1)
fmt.Println(a, b)
}
func bianli() {
var x [2][2]int = [...][2]int{{1, 2}, {3, 4}}
for k1, v1 := range x {
for k2, v2 := range v1 {
fmt.Printf("(%d,%d)=%d", k1, k2, v2)
}
fmt.Println()
}
}
// output
[[0 0 0] [0 0 0] [0 0 0] [0 0 0] [0 0 0]] [[1 2 3] [7 8 9]]
[[1 2 3] [4 5 6]] [[1 1] [2 2] [3 3]]
⚠️ range 创建了每个元素的副本,而不是直接返回对该元素的引用。
切片Slice
切片(slice)是 Golang 中一种比较特殊的数据结构,这种数据结构更便于使用和管理数据集合。切片是围绕动态数组的概念构建的,可以按需自动增长和缩小。切片的动态增长是通过内置函数 append() 来实现的,这个函数可以快速且高效地增长切片,也可以通过对切片再次切割,缩小一个切片的大小。因为切片的底层也是在连续的内存块中分配的,所以切片还能获得索引、迭代以及为垃圾回收优化的好处。
需要说明,slice 并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。
1. 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。 2. 切片的长度可以改变,因此,切片是一个可变的数组。 3. 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。 4. cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。 5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。 6. 如果 slice == nil,那么 len、cap 结果都等于 0。1. 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。 2. 切片的长度可以改变,因此,切片是一个可变的数组。 3. 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。 4. cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。 5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。 6. 如果 slice == nil,那么 len、cap 结果都等于 0。
切片声明赋值
切片的创建方式与数组的创建方式类似,区别是切片创建时[]没有数值,有数值则为数组。
// 切片声明及初始化
// 创建一个整型切片
// 其长度和容量都是 5 个元素
slice := make([]int, 5)
// 其长度为 3 个元素,容量为 5 个元素
slice := make([]int, 3, 5)
// 其长度和容量都是 3 个元素
myStr := []string{"Jack", "Mark", "Nick"}
myStr[1] = "AGou" // 改变索引为1的切片
// 创建字符串切片
// 使用空字符串初始化第 100 个元素
myStr := []string{99: ""}
// 切片声明及初始化
// 创建一个整型切片
// 其长度和容量都是 5 个元素
slice := make([]int, 5)
// 其长度为 3 个元素,容量为 5 个元素
slice := make([]int, 3, 5)
// 其长度和容量都是 3 个元素
myStr := []string{"Jack", "Mark", "Nick"}
myStr[1] = "AGou" // 改变索引为1的切片
// 创建字符串切片
// 使用空字符串初始化第 100 个元素
myStr := []string{99: ""}
⚠️ Golang 不允许创建容量小于长度的切片。
通过切片创建新的切片
通过切片创建新切片的语法如下:
slice[i:j]
slice[i:j:k]
slice[i:j]
slice[i:j:k]
其中 i 表示从 slice 的第几个元素开始切,j 控制切片的长度(j-i),k 控制切片的容量(k-i),如果没有给定 k,则表示切到底层数组的最尾部。下面是几种常见的简写形式:
slice[i:] // 从 i 切到最尾部
slice[:j] // 从最开头切到 j(不包含 j)
slice[:] // 从头切到尾,等价于复制整个 slice
slice[i:] // 从 i 切到最尾部
slice[:j] // 从最开头切到 j(不包含 j)
slice[:] // 从头切到尾,等价于复制整个 slice
让我们通过下面的例子来理解通过切片创建新的切片的本质:
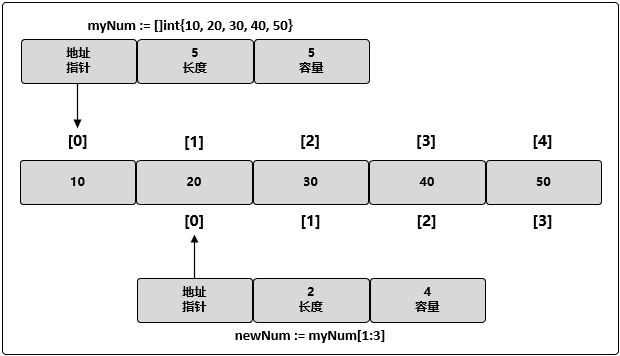
// 创建一个整型切片 // 其长度和容量都是 5 个元素 myNum := []int{10, 20, 30, 40, 50} // 创建一个新切片 // 其长度为 2 个元素,容量为 4 个元素 newNum := slice[1:3]// 创建一个整型切片 // 其长度和容量都是 5 个元素 myNum := []int{10, 20, 30, 40, 50} // 创建一个新切片 // 其长度为 2 个元素,容量为 4 个元素 newNum := slice[1:3]执行上面的代码后,我们有了两个切片,它们共享同一段底层数组,但通过不同的切片会看到底层数组的不同部分:
ℹ️截取新切片时的原则是 "左含右不含"。所以 newNum 是从 myNum 的 index=1 处开始截取,截取到 index=3 的前一个元素,也就是不包含 index=3 这个元素。所以,新的 newNum 是由 myNum 中的第2个元素、第3个元素组成的新的切片构,长度为 2,容量为 4。切片 myNum 能够看到底层数组全部 5 个元素的容量,而 newNum 能看到的底层数组的容量只有 4 个元素。newNum 无法访问到底层数组的第一个元素。所以,对 newNum 来说,那个元素就是不存在的。
切片扩容
myNum := []int{10, 20, 30, 40, 50}
// 创建新的切片,其长度为 2 个元素,容量为 4 个元素
newNum := myNum[1:3]
// 使用原有的容量来分配一个新元素
// 将新元素赋值为 60
newNum = append(newNum, 60)
myNum := []int{10, 20, 30, 40, 50}
// 创建新的切片,其长度为 2 个元素,容量为 4 个元素
newNum := myNum[1:3]
// 使用原有的容量来分配一个新元素
// 将新元素赋值为 60
newNum = append(newNum, 60)
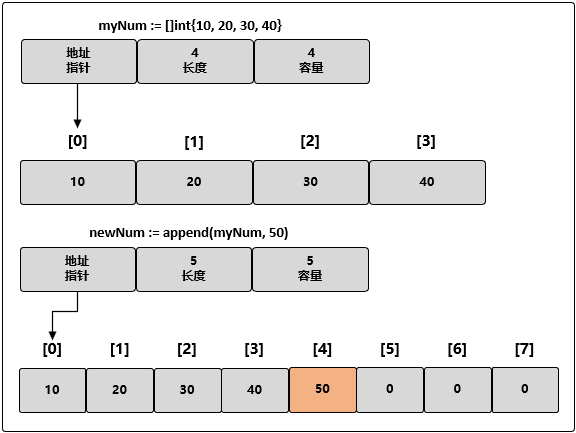
如果切片的底层数组没有足够的可用容量,append() 函数会创建一个新的底层数组,将被引用的现有的值复制到新数组里,再追加新的值,此时 append 操作同时增加切片的长度和容量:
// 创建一个长度和容量都是 4 的整型切片 myNum := []int{10, 20, 30, 40} // 向切片追加一个新元素 // 将新元素赋值为 50 newNum := append(myNum, 50)// 创建一个长度和容量都是 4 的整型切片 myNum := []int{10, 20, 30, 40} // 向切片追加一个新元素 // 将新元素赋值为 50 newNum := append(myNum, 50)当这个 append 操作完成后,newSlice 拥有一个全新的底层数组,这个数组的容量是原来的两倍:
函数 append() 会智能地处理底层数组的容量增长。在切片的容量小于 1000 个元素时,总是会成倍地增加容量。一旦元素个数超过 1000,容量的增长因子会设为 1.25,也就是会每次增加 25%的容量(随着语言的演化,这种增长算法可能会有所改变)。
将一个切片追加到另外一个切片:
slice1 := []int{1,2}
slice2 := []int{3,4}
slice3 = append(slice1,slice2...) // ... 不要漏了。。。
slice1 := []int{1,2}
slice2 := []int{3,4}
slice3 = append(slice1,slice2...) // ... 不要漏了。。。
遍历切片
myNum := []int{10, 20, 30, 40, 50}
// 迭代每一个元素,并显示其值
for index, value := range myNum {
fmt.Printf("index: %d value: %d\n", index, value)
}
myNum := []int{10, 20, 30, 40, 50}
// 迭代每一个元素,并显示其值
for index, value := range myNum {
fmt.Printf("index: %d value: %d\n", index, value)
}
切片拷贝
它表示把切片 src 中的元素拷贝到切片 dst 中,返回值为拷贝成功的元素个数。如果 src 比 dst 长,就截断;如果 src 比 dst 短,则只拷贝 src 那部分:
num1 := []int{10, 20, 30}
num2 := make([]int, 5)
count := copy(num2, num1)
fmt.Println(count)
fmt.Println(num2)
num1 := []int{10, 20, 30}
num2 := make([]int, 5)
count := copy(num2, num1)
fmt.Println(count)
fmt.Println(num2)
运行这段单面,输出的结果为:
3
[10 20 30 0 0]
3
[10 20 30 0 0]
3 表示拷贝成功的元素个数。
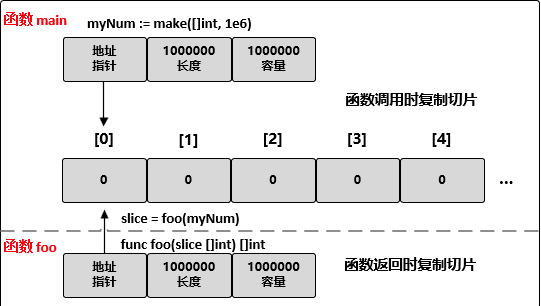
将切片传递给函数
myNum := make([]int, 1e6)
// 将 myNum 传递到函数 foo()
slice = foo(myNum)
// 函数 foo() 接收一个整型切片,并返回这个切片
func foo(slice []int) []int {
...
return slice
}
myNum := make([]int, 1e6)
// 将 myNum 传递到函数 foo()
slice = foo(myNum)
// 函数 foo() 接收一个整型切片,并返回这个切片
func foo(slice []int) []int {
...
return slice
}
map映射
映射是一个数据集合,所以可以是使用类似处理数组和切片的方式来迭代映射中的元素。但映射是无序集合,所以即使以同样的顺序保存键值对,迭代映射时,元素的顺序可能会不一样。无序的原因是映射的实现使用了哈希表。
// 使用make函数初始化映射
// 创建一个映射,键的类型是 string,值的类型是 int
myMap := make(map[string]int)
// 使用字面量来初始化映射
// 创建一个映射,键和值的类型都是 string
// 使用两个键值对初始化映射
myMap := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}
myMap["Yellow"] = "#df1d25"
// 使用make函数初始化映射
// 创建一个映射,键的类型是 string,值的类型是 int
myMap := make(map[string]int)
// 使用字面量来初始化映射
// 创建一个映射,键和值的类型都是 string
// 使用两个键值对初始化映射
myMap := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}
myMap["Yellow"] = "#df1d25"
与切片类似,可以通过声明一个未初始化的映射来创建一个值为 nil 的映射(一般称为 nil 映射),nil 映射不能用于存储键值对:
// 通过声明映射创建一个 nil 映射
var myColors map[string]string
// 将 Red 的代码加入到映射
myColors["Red"] = "#da1337"
// 通过声明映射创建一个 nil 映射
var myColors map[string]string
// 将 Red 的代码加入到映射
myColors["Red"] = "#da1337"
运行这段代码会产生一个运行时错误:panic: assignment to entry in nil map
映射CRUD
// 查找某个键是否存在
if v, ok := mymap["Red"]; ok { // 返回值为一个value值和一个boolean值,存在则为true
fmt.Print(v)
}
// 添加修改键值
mymap["yellow"] = "green" // 如果yellow键存在则修改其值,如果不存在,则添加该键值对
// 删除
delete(mymap, "yellow")
// 查找某个键是否存在
if v, ok := mymap["Red"]; ok { // 返回值为一个value值和一个boolean值,存在则为true
fmt.Print(v)
}
// 添加修改键值
mymap["yellow"] = "green" // 如果yellow键存在则修改其值,如果不存在,则添加该键值对
// 删除
delete(mymap, "yellow")
遍历映射
for k,v := range mymap{
fmt.Printf("%v: %v",k,v)
}
for k,v := range mymap{
fmt.Printf("%v: %v",k,v)
}
将映射传递给函数
removeMymap(mymap, "red")
func removeMymap(mymap map[string]string, key string) {
delete(mymap, key)
}
removeMymap(mymap, "red")
func removeMymap(mymap map[string]string, key string) {
delete(mymap, key)
}
map容量
和数组不同,map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity,格式如下:
make(map[keytype]valuetype, cap)
map2 := make(map[string]float, 100)
make(map[keytype]valuetype, cap)
map2 := make(map[string]float, 100)
当 map 增长到容量上限的时候,如果再增加新的 key-value,map 的大小会自动加 1,所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
用切片作为 map 的值
既然一个 key 只能对应一个 value,而 value 又是一个原始类型,那么如果一个 key 要对应多个值怎么办?例如,当我们要处理 unix 机器上的所有进程,以父进程(pid 为整形)作为 key,所有的子进程(以所有子进程的 pid 组成的切片)作为 value。通过将 value 定义为 []int 类型或者其他类型的切片,就可以优雅的解决这个问题,示例代码如下所示:
mp1 := make(map[int][]int)
mp2 := make(map[int]*[]int)
mp1 := make(map[int][]int)
mp2 := make(map[int]*[]int)
多维映射
var mymap map[string]map[string]string
mymap := map[string]map[string]string{"AGou-ops":{"id":"1","age":"18"}}
mymap := map[string]map[string]string
var mymap map[string]map[string]string
mymap := map[string]map[string]string{"AGou-ops":{"id":"1","age":"18"}}
mymap := map[string]map[string]string
流程控制及循环
if
// 前置语句可以省略,而且不必就是定义或者初始化变量,使用fmt.Print()都可以
if [前置语句] ;布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} else if{
} else {
}
// 前置语句可以省略,而且不必就是定义或者初始化变量,使用fmt.Print()都可以
if [前置语句] ;布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} else if{
} else {
}
⚠️ 不支持三元操作符(三目运算符) "a > b ? a : b"。
switch
switch var1 {
case val1:
...
case val2:
...
default:
...
}
switch var1 {
case val1:
...
case val2:
...
default:
...
}
type switch
switch x.(type){
case type:
statement(s)
fallthrough // 如果希望执行下面的case语句时,可以使用fallthrough
case type:
statement(s)
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s)
}
switch x.(type){
case type:
statement(s)
fallthrough // 如果希望执行下面的case语句时,可以使用fallthrough
case type:
statement(s)
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s)
}
select
select 语句类似于 switch 语句,但是select会随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。select 是Go中的一个控制结构,类似于用于通信的switch语句。每个case必须是一个通信操作,要么是发送要么是接收。 select 随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。一个默认的子句应该总是可运行的。
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
for
for init; condition; post { }
// init: 一般为赋值表达式,给控制变量赋初值;
// condition: 关系表达式或逻辑表达式,循环控制条件;
// post: 一般为赋值表达式,给控制变量增量或减量。
// for语句执行过程如下:
// ①先对表达式 init 赋初值;
// ②判别赋值表达式 init 是否满足给定 condition 条件,若其值为真,满足循环条件,则执行循环体内语句,然后执行 post,进入第二次循环,再判别 condition;否则判断 condition 的值为假,不满足条件,就终止for循环,执行循环体外语句。
for init; condition; post { }
// init: 一般为赋值表达式,给控制变量赋初值;
// condition: 关系表达式或逻辑表达式,循环控制条件;
// post: 一般为赋值表达式,给控制变量增量或减量。
// for语句执行过程如下:
// ①先对表达式 init 赋初值;
// ②判别赋值表达式 init 是否满足给定 condition 条件,若其值为真,满足循环条件,则执行循环体内语句,然后执行 post,进入第二次循环,再判别 condition;否则判断 condition 的值为假,不满足条件,就终止for循环,执行循环体外语句。
range
Golang range类似迭代器操作,返回 (索引, 值) 或 (键, 值)。
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
for key, value := range oldMap {
newMap[key] = value
}
for key, value := range oldMap {
newMap[key] = value
}
for 和 for range有什么区别?
主要是使用场景不同,for可以
- 遍历
array和slice- 遍历key为整型递增的
map- 遍历
string
for range可以完成所有for可以做的事情,却能做到for不能做的,包括:
遍历key为
string类型的map并同时获取key和value遍历
channel
goto
Label 在 break 和 continue 语句中是可选参数,而在 goto 语句中是必传的参数。Label 只在声明它的函数中有效。只要函数中声明了 Label ,那它在该函数的整个作用域都有效。
func goto_test() {
fmt.Println(1)
goto End
fmt.Println(2)
End:
fmt.Println(3)
}
// output
1
3
func goto_test() {
fmt.Println(1)
goto End
fmt.Println(2)
End:
fmt.Println(3)
}
// output
1
3
Label 的标识符和其他标识符具有不同的命名空间,所以不会与变量标识符等发生冲突。下面这段代码同时在 Label 和变量声明中都使用 x 作为标识符:
x := 1
goto x
x:
fmt.Println(x)
x := 1
goto x
x:
fmt.Println(x)
死循环
golang死循环的几种写法:
for{ // or:
}
for{ // or:
}
参考链接
Go 语言中文文档:http://www.topgoer.com/
Go 语言中文网:https://studygolang.com/
【引用】Golang 切片入门https://www.cnblogs.com/sparkdev/p/10704614.html
Golang 映射入门:https://www.cnblogs.com/sparkdev/p/10749542.html