Appearance
MySQL快速手册
mysql -h <mysql_server_addr> -P <PORT> -u <USER> -p <PASSWORD>
mysql -h <mysql_server_addr> -P <PORT> -u <USER> -p <PASSWORD>
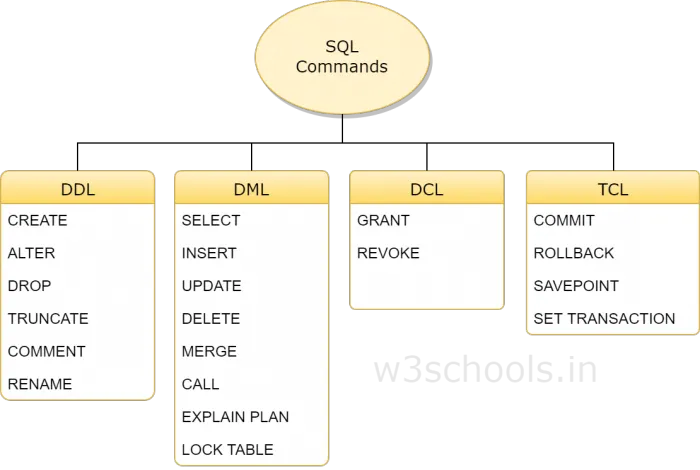
- DDL(Data Definition Languages):数据库定义语句:用来创建数据库中的表、索引、视图、存储过程、触发器等
- DML(Data Manipulation Language):数据操纵语句:用来查询、添加、更新、删除等
- DCL(Data Control Language):数据控制语句:用于授权/撤销数据库及其字段的权限
- TCL(Transaction Control Language):事务控制语句:用于控制事务
- DQL(Data Query Language):数据查询语言,select, from, where,order by, having,asc|desc
基础
-- 全局 --
SHOW processlist; -- 显示哪些线程正在运行
SHOW master status\G;
SHOW variables like 'server_id'; -- 显示系统变量
SHOW GLOBAL variables like '%log_warning%';
SELECT @@global.autocommit; -- 显示全局变量
SHOW ENGINES;
SHOW ENGINES <ENGINE_NAME> <LOGS|StATUS>; -- 显示存储引擎的日志或者状态信息
SELECT now(),user(),version();
SELECT * from information_schema.VIEWS; -- 查看视图
SELECT * from information_schema.TABLES; -- 查看数据库所有表
EXPLAIN <sql语句>; --
-- 慢日志相关
show variables like '%slow_query_log%';
-- 库级 --
CREATE DATABASE IF NOT EXISTS <DATABASE_NAME> DEFAULT CHARSET utf8 COLLATE utf8_general_ci; -- 创建数据库并指定字符集
SHOW CREATE DATABASE <DATABASE>;
FLUSH PRIVILEGES; -- 刷新权限
SELECT database(); -- 当前选择的数据库
-- 表级 --
DESC <TABLE_NAME>; -- 表结构、使用describe、show columns from <table_name>能达到相同效果
SELECT user,host,password FROM mysql.user; -- 显示表中的制定字段
SHOW TABLES FROM <TABLE_NAME>; -- 显示所有表
SHOW TABLE STATUS [FROM <DATABASE_NAME>] [LIKE 'PATTERN']; -- 显示表状态
ALTER TABLE <TABLE_NAME> <...OPTIONS...> -- 修改表选项,alter table test ENGINE=MYISAM;
RENAME TABLE <old_TABLE_NAME> TO <new_TABLE_NAME>;
RENAME TABLE <old_TABLE_NAME> TO <DATABASE_NAME.TABLE_NAME>; -- 可以将表移动到另外一个数据库
CREATE TABLE <TABLE_NAME> LIKE <TABLE_NAME>; -- 复制表结构
CREATE TABLE <TABLE_NAME> AS SELECT * FROM <TABLE_NAME>; -- 复制表结构及表数据
CREATE TABLE IF NOT EXISTS `test_table`(
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`addr` VARCHAR(40) NOT NULL,
`date` DATE,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE <TABLE_NAME> <...OPTIONS...>;
/* 操作名
ADD COLUMN 字段定义 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
DROP [COLUMN] 字段名 -- 删除字段
MODIFY [COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE [COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
* DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
*/
DROP TABLE [IF EXISTS] <TABLE_NAME...>; -- 删除表
TRUNCATE TABLE <TABLE_NAME>; -- 清空表数据,不删除表结构
DELETE FROM <TABLE_NAME>; -- 清空表数据,不删除表结构
-- 检查表是否有错误
CHECK TABLE <TABLE_NAME1>,<TBL_NAME2>...;
-- 刷新表数据
FLUSH TABLES WITH READ LOCK;
UNLOCK TABLES;
-- 释放表空间,使用delete时未释放磁盘空间,但是下次插入数据的时候,仍然可以使用这部分空间。
OPTIMIZE TABLE <TABLE_NAME1>,<TBL_NAME2> <...OPTIONS...>;
-- 分析表
ANALYZE TABLE <TABLE_NAME1>,<TBL_NAME2> <...OPTIONS...>;
-- 修复表
REPAIR TABLE <TABLE_NAME1>,<TBL_NAME2> <...OPTIONS...>;
-- 全局 --
SHOW processlist; -- 显示哪些线程正在运行
SHOW master status\G;
SHOW variables like 'server_id'; -- 显示系统变量
SHOW GLOBAL variables like '%log_warning%';
SELECT @@global.autocommit; -- 显示全局变量
SHOW ENGINES;
SHOW ENGINES <ENGINE_NAME> <LOGS|StATUS>; -- 显示存储引擎的日志或者状态信息
SELECT now(),user(),version();
SELECT * from information_schema.VIEWS; -- 查看视图
SELECT * from information_schema.TABLES; -- 查看数据库所有表
EXPLAIN <sql语句>; --
-- 慢日志相关
show variables like '%slow_query_log%';
-- 库级 --
CREATE DATABASE IF NOT EXISTS <DATABASE_NAME> DEFAULT CHARSET utf8 COLLATE utf8_general_ci; -- 创建数据库并指定字符集
SHOW CREATE DATABASE <DATABASE>;
FLUSH PRIVILEGES; -- 刷新权限
SELECT database(); -- 当前选择的数据库
-- 表级 --
DESC <TABLE_NAME>; -- 表结构、使用describe、show columns from <table_name>能达到相同效果
SELECT user,host,password FROM mysql.user; -- 显示表中的制定字段
SHOW TABLES FROM <TABLE_NAME>; -- 显示所有表
SHOW TABLE STATUS [FROM <DATABASE_NAME>] [LIKE 'PATTERN']; -- 显示表状态
ALTER TABLE <TABLE_NAME> <...OPTIONS...> -- 修改表选项,alter table test ENGINE=MYISAM;
RENAME TABLE <old_TABLE_NAME> TO <new_TABLE_NAME>;
RENAME TABLE <old_TABLE_NAME> TO <DATABASE_NAME.TABLE_NAME>; -- 可以将表移动到另外一个数据库
CREATE TABLE <TABLE_NAME> LIKE <TABLE_NAME>; -- 复制表结构
CREATE TABLE <TABLE_NAME> AS SELECT * FROM <TABLE_NAME>; -- 复制表结构及表数据
CREATE TABLE IF NOT EXISTS `test_table`(
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`addr` VARCHAR(40) NOT NULL,
`date` DATE,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE <TABLE_NAME> <...OPTIONS...>;
/* 操作名
ADD COLUMN 字段定义 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
DROP [COLUMN] 字段名 -- 删除字段
MODIFY [COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE [COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
* DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
*/
DROP TABLE [IF EXISTS] <TABLE_NAME...>; -- 删除表
TRUNCATE TABLE <TABLE_NAME>; -- 清空表数据,不删除表结构
DELETE FROM <TABLE_NAME>; -- 清空表数据,不删除表结构
-- 检查表是否有错误
CHECK TABLE <TABLE_NAME1>,<TBL_NAME2>...;
-- 刷新表数据
FLUSH TABLES WITH READ LOCK;
UNLOCK TABLES;
-- 释放表空间,使用delete时未释放磁盘空间,但是下次插入数据的时候,仍然可以使用这部分空间。
OPTIMIZE TABLE <TABLE_NAME1>,<TBL_NAME2> <...OPTIONS...>;
-- 分析表
ANALYZE TABLE <TABLE_NAME1>,<TBL_NAME2> <...OPTIONS...>;
-- 修复表
REPAIR TABLE <TABLE_NAME1>,<TBL_NAME2> <...OPTIONS...>;
拓展:
- 查看某表中的字段是否存在
SELECT IF(count(*) = 1, 'Exist','Not Exist') AS result FROM information_schema.columns WHERE table_schema = '<DB_NAME>' AND table_name = '<TABLE_NAME>' AND column_name = '<COLUMN_NAME>';SELECT IF(count(*) = 1, 'Exist','Not Exist') AS result FROM information_schema.columns WHERE table_schema = '<DB_NAME>' AND table_name = '<TABLE_NAME>' AND column_name = '<COLUMN_NAME>';
DELETE和TRUNCATE的区别a. 不带where参数的
delete语句可以删除mysql表中所有内容,使用truncate table也可以清空mysql表中所有内容。b. 效率上
truncate比delete快,但truncate删除后不记录mysql日志,不可以恢复数据。c.
delete语句是数据库操作语言(dml),这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。truncate、drop是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。d.
delete的效果有点像将mysql表中所有记录一条一条删除到删完,而truncate相当于保留mysql表的结构,重新创建了这个表,所有的状态都相当于新表。
CRUD
-- 增
INSERT INTO <TABLE_NAME> [(字段列表)] VALUES (值列表)[, (值列表), ...]
-- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。
-- 可同时插入多条数据记录!
/* REPLACE 与 INSERT 使用语法完全一样,其区别就是前者发现如果表中存在该数据,则会先删除该数据,然后再进行插入,而后者如若发现数据重复,则会报错。
*/
INSERT INTO <TABLE_NAME> SET 字段名=值[, 字段名=值, ...]
-- 删
DELETE FROM <TABLE_NAME> [删除条件子句]
没有条件子句,则会删除全部
-- 改
UPDATE <TABLE_NAME> SET 字段名=新值[,字段名=新值] [更新条件]
-- 查
SELECT 字段列表 FROM <TABLE_NAME> [其他子句]
-- 可来自多个表的多个字段
-- 其他子句可以不使用
-- 字段列表可以用*代替,表示所有字段
-- 增
INSERT INTO <TABLE_NAME> [(字段列表)] VALUES (值列表)[, (值列表), ...]
-- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。
-- 可同时插入多条数据记录!
/* REPLACE 与 INSERT 使用语法完全一样,其区别就是前者发现如果表中存在该数据,则会先删除该数据,然后再进行插入,而后者如若发现数据重复,则会报错。
*/
INSERT INTO <TABLE_NAME> SET 字段名=值[, 字段名=值, ...]
-- 删
DELETE FROM <TABLE_NAME> [删除条件子句]
没有条件子句,则会删除全部
-- 改
UPDATE <TABLE_NAME> SET 字段名=新值[,字段名=新值] [更新条件]
-- 查
SELECT 字段列表 FROM <TABLE_NAME> [其他子句]
-- 可来自多个表的多个字段
-- 其他子句可以不使用
-- 字段列表可以用*代替,表示所有字段
SELECT
/* SELECT */ ------------------
SELECT [ALL|DISTINCT] select_expr FROM -> WHERE --> GROUP BY [合计函数] -> HAVING -> ORDER BY -> LIMIT
select_expr
-- 可以用 * 表示所有字段。
select * from tb;
-- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
select stu, 29+25, now() from tb;
-- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
- 使用 as 关键字,也可省略 as.
select stu+10 as add10 from tb;
FROM 子句
用于标识查询来源。
-- 可以为表起别名。使用as关键字。
SELECT * FROM tb1 AS tt, tb2 AS bb;
-- from子句后,可以同时出现多个表。
-- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
SELECT * FROM tb1, tb2;
-- 向优化符提示如何选择索引
USE INDEX、IGNORE INDEX、FORCE INDEX
SELECT * FROM table1 USE INDEX (key1,key2) WHERE key1=1 AND key2=2 AND key3=3;
SELECT * FROM table1 IGNORE INDEX (key3) WHERE key1=1 AND key2=2 AND key3=3;
WHERE 子句
-- 从from获得的数据源中进行筛选。
-- 整型1表示真,0表示假。
-- 表达式由运算符和运算数组成。
-- 运算数:变量(字段)、值、函数返回值
-- 运算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
is/is not 加上ture/false/unknown,检验某个值的真假
<=>与<>功能相同,<=>可用于null比较
-- in
SELECT * FROM <TBL_NAME> a WHERE (a.<COLUMN1>,A.<COLUMN2>) IN/= (SELECT ...)
UNION 子句
-- 从多个表中查询出相似结构的数据,并且返回一个结果集
-- 从单个表中多次SELECT查询,将结果合并成一个结果集返回。
-- Union检索遇到不一致的字段名称时候,会使用第一条SELECT的查询字段名称,或者你使用别名来改变查询字段名称。
-- 额外参数:
-- ALL:可选,返回所有结果集,包含重复数据
-- DISTINCT:可选,删除结果集中的重复数据,但默认情况下UNION操作符会自动删除重复数据,故此项参数加不加没什么影响
-- 'str' AS TABLE_NAME:用于区分多个联合表的标识字段列
(SELECT *,'tbl1' AS TABLE_NAME FROM <TBL_NAME> a WHERE ...) UNION [ALL|DISTINCT] (SELECT *,'tbl2' AS TABLE_NAME ...) ORDER BY id DESC
GROUP BY 子句, 分组子句
GROUP BY 字段/别名 [排序方式]
分组后会进行排序。排序规则,ASC升序(`DEFAULT`),DESC降序
SELECT user_id 用户id, count(id) 数量 FROM tbl GROUP BY user_id;
以下[合计函数]需配合 GROUP BY 使用:
count 返回不同的非NULL值数目 count(*)、count(字段)
sum 求和
max 求最大值
min 求最小值
avg 求平均值
group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
HAVING 子句,条件子句
`与 where 功能、用法相同,执行时机不同。
where 在开始时执行检测数据,对原数据进行过滤。
having 对筛选出的结果再次进行过滤。
having 字段必须是查询出来的,where 字段必须是数据表存在的。
where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
where 不可以使用合计函数。一般需用合计函数才会用 having`
SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
ORDER BY 子句,排序子句
order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
升序:ASC,降序:DESC
支持多个字段的排序。
LIMIT 子句,限制结果数量子句
仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
limit 起始位置, 获取条数
省略第一个参数,表示从索引0开始。limit 获取条数
DISTINCT, ALL 选项
distinct 去除重复记录
默认为 all, 全部记录
/* SELECT */ ------------------
SELECT [ALL|DISTINCT] select_expr FROM -> WHERE --> GROUP BY [合计函数] -> HAVING -> ORDER BY -> LIMIT
select_expr
-- 可以用 * 表示所有字段。
select * from tb;
-- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
select stu, 29+25, now() from tb;
-- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
- 使用 as 关键字,也可省略 as.
select stu+10 as add10 from tb;
FROM 子句
用于标识查询来源。
-- 可以为表起别名。使用as关键字。
SELECT * FROM tb1 AS tt, tb2 AS bb;
-- from子句后,可以同时出现多个表。
-- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
SELECT * FROM tb1, tb2;
-- 向优化符提示如何选择索引
USE INDEX、IGNORE INDEX、FORCE INDEX
SELECT * FROM table1 USE INDEX (key1,key2) WHERE key1=1 AND key2=2 AND key3=3;
SELECT * FROM table1 IGNORE INDEX (key3) WHERE key1=1 AND key2=2 AND key3=3;
WHERE 子句
-- 从from获得的数据源中进行筛选。
-- 整型1表示真,0表示假。
-- 表达式由运算符和运算数组成。
-- 运算数:变量(字段)、值、函数返回值
-- 运算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
is/is not 加上ture/false/unknown,检验某个值的真假
<=>与<>功能相同,<=>可用于null比较
-- in
SELECT * FROM <TBL_NAME> a WHERE (a.<COLUMN1>,A.<COLUMN2>) IN/= (SELECT ...)
UNION 子句
-- 从多个表中查询出相似结构的数据,并且返回一个结果集
-- 从单个表中多次SELECT查询,将结果合并成一个结果集返回。
-- Union检索遇到不一致的字段名称时候,会使用第一条SELECT的查询字段名称,或者你使用别名来改变查询字段名称。
-- 额外参数:
-- ALL:可选,返回所有结果集,包含重复数据
-- DISTINCT:可选,删除结果集中的重复数据,但默认情况下UNION操作符会自动删除重复数据,故此项参数加不加没什么影响
-- 'str' AS TABLE_NAME:用于区分多个联合表的标识字段列
(SELECT *,'tbl1' AS TABLE_NAME FROM <TBL_NAME> a WHERE ...) UNION [ALL|DISTINCT] (SELECT *,'tbl2' AS TABLE_NAME ...) ORDER BY id DESC
GROUP BY 子句, 分组子句
GROUP BY 字段/别名 [排序方式]
分组后会进行排序。排序规则,ASC升序(`DEFAULT`),DESC降序
SELECT user_id 用户id, count(id) 数量 FROM tbl GROUP BY user_id;
以下[合计函数]需配合 GROUP BY 使用:
count 返回不同的非NULL值数目 count(*)、count(字段)
sum 求和
max 求最大值
min 求最小值
avg 求平均值
group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
HAVING 子句,条件子句
`与 where 功能、用法相同,执行时机不同。
where 在开始时执行检测数据,对原数据进行过滤。
having 对筛选出的结果再次进行过滤。
having 字段必须是查询出来的,where 字段必须是数据表存在的。
where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
where 不可以使用合计函数。一般需用合计函数才会用 having`
SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
ORDER BY 子句,排序子句
order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
升序:ASC,降序:DESC
支持多个字段的排序。
LIMIT 子句,限制结果数量子句
仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
limit 起始位置, 获取条数
省略第一个参数,表示从索引0开始。limit 获取条数
DISTINCT, ALL 选项
distinct 去除重复记录
默认为 all, 全部记录
用户权限
CREATE USER auditor@localhost IDENTIFIED BY 'newpasswd';
GRANT ALL ON yiibaidb.* TO auditor@localhost;
GRANT CREATE,EXECUTE,INSERT,DELETE,SELECT ON *.* TO usertest1@localhost;
GRANT CREATE,EXECUTE,INSERT,DELETE,SELECT ON *.* TO usertest1@'%' IDENTIFIED BY 'newpasswd';
SHOW GRANTS FOR usertest1@'%';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '1234' WITH GRANT OPTION;
flush privileges;
CREATE USER auditor@localhost IDENTIFIED BY 'newpasswd';
GRANT ALL ON yiibaidb.* TO auditor@localhost;
GRANT CREATE,EXECUTE,INSERT,DELETE,SELECT ON *.* TO usertest1@localhost;
GRANT CREATE,EXECUTE,INSERT,DELETE,SELECT ON *.* TO usertest1@'%' IDENTIFIED BY 'newpasswd';
SHOW GRANTS FOR usertest1@'%';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '1234' WITH GRANT OPTION;
flush privileges;
详情查看[MySQL Auth CLI.md](./MySQL Auth CLI.md)
字符集编码
-- 查看字符集编码
SHOW VARIABLES LIKE 'character_set%';
-- 创建数据库时指定字符集
CREATE DATABASE IF NOT EXISTS <DATABASE_NAME> CHARACTER SET <CHAR_SET>;
-- 修改数据库的字符集
ALTER DATABASE <DATABASE_NAME> CHARACTER SET <CHAR_SET>;
-- 改字符集
SET character_set_client = utf8; -- 客户端向服务器端发送数据时使用的编码
SET character_set_results = utf8; -- 服务器端将结果返回给客户端时所使用的编码
SET character_set_connection = utf8; -- 连接层所使用的编码
SET NAMES utf8; -- 该命令相当于一次执行上面三条命令 --
SET character_set_database = utf8; -- 数据库使用的编码
SET character_set_server = utf8; -- 服务器字符集,配置文件指定货建库建表指定。
SET character_set_system = utf8; -- 系统字符集
character_set_filesystem -- 文件系统所使用的字符集
-- 查看字符集编码
SHOW VARIABLES LIKE 'character_set%';
-- 创建数据库时指定字符集
CREATE DATABASE IF NOT EXISTS <DATABASE_NAME> CHARACTER SET <CHAR_SET>;
-- 修改数据库的字符集
ALTER DATABASE <DATABASE_NAME> CHARACTER SET <CHAR_SET>;
-- 改字符集
SET character_set_client = utf8; -- 客户端向服务器端发送数据时使用的编码
SET character_set_results = utf8; -- 服务器端将结果返回给客户端时所使用的编码
SET character_set_connection = utf8; -- 连接层所使用的编码
SET NAMES utf8; -- 该命令相当于一次执行上面三条命令 --
SET character_set_database = utf8; -- 数据库使用的编码
SET character_set_server = utf8; -- 服务器字符集,配置文件指定货建库建表指定。
SET character_set_system = utf8; -- 系统字符集
character_set_filesystem -- 文件系统所使用的字符集
修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '新密码';
update user set password=password("12345") where user="root";
/* 忘记root密码,停数据库 使用*/
mysqld_safe --skip-grant-tables
set password = password("newpasswd");
ALTER USER 'root'@'localhost' IDENTIFIED BY '新密码';
update user set password=password("12345") where user="root";
/* 忘记root密码,停数据库 使用*/
mysqld_safe --skip-grant-tables
set password = password("newpasswd");
详情查看[MySQL Auth CLI.md](./MySQL Auth CLI.md)
视图
CREATE
[OR REPLACE] -- 替换已有视图
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] -- 视图选择算法,默认为为定义的,merge表示合并,temptable表示临时表
[DEFINER = user]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION] -- cascade是默认值,表示更新视图的时候,要满足视图和表的相关条件,local表示更新视图的时候,要满足该视图定义的一个条件即可,推荐使用CHECK OPTION
-- 示例
MariaDB root@win:test> create view v_test_data(完整名字,邮箱,IP地址) as
-> select concat_ws(" ",first_name,last_name),email,ip_address from test_data
-> where id<50
-> with check option; -- with check option约束限制,保证更新视图是在该视图的权限范围之内。
-- 修改视图
create or replace view <view_name> as ...;
alter view <view_name> as ...;
CREATE
[OR REPLACE] -- 替换已有视图
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] -- 视图选择算法,默认为为定义的,merge表示合并,temptable表示临时表
[DEFINER = user]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION] -- cascade是默认值,表示更新视图的时候,要满足视图和表的相关条件,local表示更新视图的时候,要满足该视图定义的一个条件即可,推荐使用CHECK OPTION
-- 示例
MariaDB root@win:test> create view v_test_data(完整名字,邮箱,IP地址) as
-> select concat_ws(" ",first_name,last_name),email,ip_address from test_data
-> where id<50
-> with check option; -- with check option约束限制,保证更新视图是在该视图的权限范围之内。
-- 修改视图
create or replace view <view_name> as ...;
alter view <view_name> as ...;
索引
-- 创建索引
create [unique] index <索引名称> on <表名>(列名[(length)]); -- unique 表示唯一索引,如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类型,必须指定length。
alter <表名> add [unique] index <索引名称> on (列名[(length)]);
-- 删除索引
drop index <索引名称> on <表名>;
-- 查看索引
show index from <表名>;
-- 修改索引,删除索引后重建索引
-- 创建索引
create [unique] index <索引名称> on <表名>(列名[(length)]); -- unique 表示唯一索引,如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类型,必须指定length。
alter <表名> add [unique] index <索引名称> on (列名[(length)]);
-- 删除索引
drop index <索引名称> on <表名>;
-- 查看索引
show index from <表名>;
-- 修改索引,删除索引后重建索引
变量
-- 赋值,带@表示全局变量,不带表示局部变量
set @变量名='值';
set @变量名:='值';
select @变量名:='值';
select '值' into @变量名 [from tbl];
-- 取值
select @变量名;
-- 赋值,带@表示全局变量,不带表示局部变量
set @变量名='值';
set @变量名:='值';
select @变量名:='值';
select '值' into @变量名 [from tbl];
-- 取值
select @变量名;
行数
USE information_schema;
SELECT TABLE_NAME,table_rows FROM TABLES WHERE TABLE_SCHEMA = 'mysql' ORDER BY table_rows DESC;
-- 查看单表行数
SELECT TABLE_NAME,table_rows FROM information_schema.tables WHERE TABLE_NAME = 'history' ORDER BY table_rows;
SELECT TABLE_NAME,table_rows FROM TABLES WHERE TABLE_NAME = 'orders' ORDER BY table_rows ;
SELECT TABLE_NAME,table_rows
FROM TABLES WHERE TABLE_NAME = 'books' ORDER BY table_rows ;
SELECT TABLE_NAME,table_rows FROM TABLES WHERE TABLE_NAME = 'book_parts' ORDER BY table_rows ;
USE information_schema;
SELECT TABLE_NAME,table_rows FROM TABLES WHERE TABLE_SCHEMA = 'mysql' ORDER BY table_rows DESC;
-- 查看单表行数
SELECT TABLE_NAME,table_rows FROM information_schema.tables WHERE TABLE_NAME = 'history' ORDER BY table_rows;
SELECT TABLE_NAME,table_rows FROM TABLES WHERE TABLE_NAME = 'orders' ORDER BY table_rows ;
SELECT TABLE_NAME,table_rows
FROM TABLES WHERE TABLE_NAME = 'books' ORDER BY table_rows ;
SELECT TABLE_NAME,table_rows FROM TABLES WHERE TABLE_NAME = 'book_parts' ORDER BY table_rows ;
查看存储过程和函数
select `name` from mysql.proc where db = 'xx' and `type` = 'PROCEDURE' ; #存储过程
select `name` from mysql.proc where db = 'xx' and `type` = 'FUNCTION' ; #函数
show procedure status; #存储过程
show function status; #函数
-- 查看存储过程或函数的创建代码
show create procedure proc_name;
show create function func_name;
select `name` from mysql.proc where db = 'xx' and `type` = 'PROCEDURE' ; #存储过程
select `name` from mysql.proc where db = 'xx' and `type` = 'FUNCTION' ; #函数
show procedure status; #存储过程
show function status; #函数
-- 查看存储过程或函数的创建代码
show create procedure proc_name;
show create function func_name;
触发器,数据库大小
SHOW TRIGGERS [FROM db_name] [LIKE expr]
SELECT * FROM triggers T WHERE trigger_name=”mytrigger” \G
#查看数据库大小
1、进入information_schema 数据库(存放了其他的数据库的信息)
use information_schema;
2、查询所有数据的大小:
select concat(round(sum(data_length/1024/1024),2),'MB') as data from tables;
3、查看指定数据库的大小:
比如查看数据库home的大小
select concat(round(sum(data_length/1024/1024),2),'MB') as data from information_schema.tables where table_schema='home';
4、查看指定数据库的某个表的大小
比如查看数据库home中 members 表的大小
select concat(round(sum(data_length/1024/1024),2),'MB') as data from information_schema.tables where table_schema='home' and table_name='members';
5,看每个表大小
SELECT TABLE_NAME,DATA_LENGTH+INDEX_LENGTH,TABLE_ROWS,concat(round((DATA_LENGTH+INDEX_LENGTH)/1024/1024,2), 'MB') as data FROM TABLES WHERE TABLE_SCHEMA='mysql';
SHOW TRIGGERS [FROM db_name] [LIKE expr]
SELECT * FROM triggers T WHERE trigger_name=”mytrigger” \G
#查看数据库大小
1、进入information_schema 数据库(存放了其他的数据库的信息)
use information_schema;
2、查询所有数据的大小:
select concat(round(sum(data_length/1024/1024),2),'MB') as data from tables;
3、查看指定数据库的大小:
比如查看数据库home的大小
select concat(round(sum(data_length/1024/1024),2),'MB') as data from information_schema.tables where table_schema='home';
4、查看指定数据库的某个表的大小
比如查看数据库home中 members 表的大小
select concat(round(sum(data_length/1024/1024),2),'MB') as data from information_schema.tables where table_schema='home' and table_name='members';
5,看每个表大小
SELECT TABLE_NAME,DATA_LENGTH+INDEX_LENGTH,TABLE_ROWS,concat(round((DATA_LENGTH+INDEX_LENGTH)/1024/1024,2), 'MB') as data FROM TABLES WHERE TABLE_SCHEMA='mysql';
是否开启保护
SHOW VARIABLES LIKE 'sql_safe_updates';
select @@sql_safe_updates;
检查数据一致性
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --create-replicate-table --databases=ifeng --tables= -u root -p eba41b786d57213b09b12ca38ed9fa63 -h 127.0.0.1
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format \
--replicate=ifeng --create-replicate-table --databases=ifeng --tables=book_parts -u chechdb -p 123comER -h 10.89.11.152
grant all on *.* to chechdb@'10.89.%.%' identified by '123comER';
SHOW VARIABLES LIKE 'sql_safe_updates';
select @@sql_safe_updates;
检查数据一致性
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --create-replicate-table --databases=ifeng --tables= -u root -p eba41b786d57213b09b12ca38ed9fa63 -h 127.0.0.1
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format \
--replicate=ifeng --create-replicate-table --databases=ifeng --tables=book_parts -u chechdb -p 123comER -h 10.89.11.152
grant all on *.* to chechdb@'10.89.%.%' identified by '123comER';
死锁
show processlist;
1:查看当前的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
2:查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
3:查看当前等锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
show processlist;
1:查看当前的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
2:查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
3:查看当前等锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
sql
后10条数据
select id,createTime from message_filesn order by id desc limit 10;
select id,createTime from message_filesn where createTime < DATE_SUB(CURDATE(),INTERVAL 1 day) order by id asc limit 10;
SELECT DATE_SUB(CURDATE(),INTERVAL 10 day) 2018-08-19
SELECT DATE_SUB(CURDATE(),INTERVAL 1 year) 2017-08-29
SELECT DATE_SUB(CURDATE(),INTERVAL 3 month) 2018-05-29
SELECT DATE_SUB(CURDATE(),INTERVAL -1 month) 2018-09-29
释放表空间
optimize table tables_name;
改表名
alter table message_filesntest rename to message_filesn ;
后10条数据
select id,createTime from message_filesn order by id desc limit 10;
select id,createTime from message_filesn where createTime < DATE_SUB(CURDATE(),INTERVAL 1 day) order by id asc limit 10;
SELECT DATE_SUB(CURDATE(),INTERVAL 10 day) 2018-08-19
SELECT DATE_SUB(CURDATE(),INTERVAL 1 year) 2017-08-29
SELECT DATE_SUB(CURDATE(),INTERVAL 3 month) 2018-05-29
SELECT DATE_SUB(CURDATE(),INTERVAL -1 month) 2018-09-29
释放表空间
optimize table tables_name;
改表名
alter table message_filesntest rename to message_filesn ;
MySQL延迟复制
MySQL 5.6 支持延迟复制,可以在Slave服务器指定一个延迟的值。默认值为0秒。使用MASTER_DELAY 选项为CHANGE MASTERTO 设置N秒延迟。
1. 下面来实际演示,正常运行的从节点执行,设置延迟100秒
STOP SLAVE;
CHANGE MASTER TO MASTER_DELAY = 100;
START SLAVE;
SHOW SLAVE STATUS\G;
显示
SQL_Delay: 100 --延迟 100S
SQL_Remaining_Delay: NULL
2. 设置取消延迟复制
STOP SLAVE ;
CHANGE MASTER TO MASTER_DELAY=0;
START SLAVE;
SHOW SLAVE STATUS\G;
SQL_Delay: 0 --取消延迟
SQL_Remaining_Delay: NULL
MySQL 5.6 支持延迟复制,可以在Slave服务器指定一个延迟的值。默认值为0秒。使用MASTER_DELAY 选项为CHANGE MASTERTO 设置N秒延迟。
1. 下面来实际演示,正常运行的从节点执行,设置延迟100秒
STOP SLAVE;
CHANGE MASTER TO MASTER_DELAY = 100;
START SLAVE;
SHOW SLAVE STATUS\G;
显示
SQL_Delay: 100 --延迟 100S
SQL_Remaining_Delay: NULL
2. 设置取消延迟复制
STOP SLAVE ;
CHANGE MASTER TO MASTER_DELAY=0;
START SLAVE;
SHOW SLAVE STATUS\G;
SQL_Delay: 0 --取消延迟
SQL_Remaining_Delay: NULL
主从
grant replication slave,file on *.* to 'slavebak'@'1.1.1.1' identified by 'newpasswd';
show master status\G;
#在从上执行以下
change master to master_host='1.1.1.1', master_user='test', master_password='newpasswd', master_log_file='mysql-bin.000005', master_log_pos=340;
change master to master_host='1.1.1.1', master_user='slavebak', master_password='newpasswd',MASTER_AUTO_POSITION=1;
grant replication slave,file on *.* to 'slavebak'@'1.1.1.1' identified by 'newpasswd';
show master status\G;
#在从上执行以下
change master to master_host='1.1.1.1', master_user='test', master_password='newpasswd', master_log_file='mysql-bin.000005', master_log_pos=340;
change master to master_host='1.1.1.1', master_user='slavebak', master_password='newpasswd',MASTER_AUTO_POSITION=1;
xtrabackup方式备份
官方参考
https://www.percona.com/doc/percona-xtrabackup/LATEST/installation/yum_repo.html
percona-toolkit //差异
yum install -y http://www.percona.com/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm
yum install percona-xtrabackup-24 -y
innobackupex --user=root --password=cXXX --defaults-file=/etc/my.cnf /data/backup #备份
innobackupex --apply-log /data/backup/ #日志回滚
innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup #备份恢复
在配置文件中加
datadir= /data/backup/
mysql> stop slave; #停止同步
mysql> reset slave; #清除从连接信息
mysql> show slave status\G; #再查看从状态,可以看到IO和SQL线程都为NO
mysql> drop database weibo; #删除weibo库,weibo为测试数据库
此时,从库现在和新装的一样,继续前进!
正式步骤开始:
1. 主库使用xtrabackup备份
innobackupex --user=root --password=123 ./
生成一个以时间为命名的备份目录:2018-06-19_16-11-01
2. 把备份目录拷贝到从库上
3. 从库上把MySQL服务停掉,删除datadir目录,
sudo rm -rf/var/lib/mysql/
innobackupex --apply-log /data/backup/ #日志回滚
innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup #备份恢复
sudo chown mysql.mysql-R /var/lib/mysql
sudo /etc/init.d/mysql start
#查看已经正常启动
4. 在主库创建test_tb2表,模拟数据库新增数据
mysql> create tabletest_tb2(id int,name varchar(30));
5. 从备份目录中xtrabackup_info文件获取到binlog和pos位置
cat/var/lib/mysql/xtrabackup_info
binlog_pos = filename'mysql-bin.000001', position 429 #这个位置
6. 从库设置从这个日志点同步,并启动
mysql> change masterto master_host='192.168.18.212',
-> master_user='sync',
-> master_password='sync',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=429;
mysql> start slave;
mysql> show slavestatus\G;
***************************1. row ***************************
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
7. 从库查看weibo库里面的表
可以看到IO和SQL线程均为YES,说明主从配置成功。
mysql> show tables;
+---------------------------+
| Tables_in_weibo |
+---------------------------+
| test_tb |
| test_tb2 |
发现刚才模拟创建的test_tb2表已经同步过来。
#################简化####################################################
innobackupex --user=root --password=cXXX --defaults-file=/etc/my.cnf /data/backup #备份
innobackupex --apply-log /data/backup/ #日志回滚
在配置文件中加
datadir= path
注意配置文件中的path 和/data/backup 不能相同。
innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup #备份恢复
主从都开启了gtid,在设置从库的时候遇到了问题
mysql> CHANGE MASTER TO MASTER_HOST=‘xxx’,MASTER_USER='replicant',MASTER_PASSWORD=‘xxx’, MASTER_LOG_FILE='bin.000050', MASTER_LOG_POS=191;ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
解决的办法
mysql> change master to master_auto_position=0;
Query OK, 0 rows affected (0.34 sec)
mysql> CHANGE MASTER TO MASTER_HOST=‘xxx’,MASTER_USER='replicant',MASTER_PASSWORD=‘xxx’, MASTER_LOG_FILE='bin.000050', MASTER_LOG_POS=191;
Query OK, 0 rows affected, 2 warnings (0.51 sec)
mysql> START SLAVE;
Query OK, 0 rows affected (0.08 sec)
mysql> SHOW SLAVE STATUS \G
change master to master_host='10.21.8.57',master_user='mysqlsync',master_password='12345678',MASTER_AUTO_POSITION=1;
备份:
/data/bin/xtrabackup/bin/innobackupex --user=root --password=cXXX --defaults-file=/etc/my.cnf /data/backup/full/
恢复:
1:应用日志
/data/bin/xtrabackup/bin/innobackupex --apply-log /data/backup/2014-01-24_11-36-53/
2:数据恢复
/data/bin/xtrabackup/bin/innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup/2014-01-24_11-36-53/
3:
chown -R mysql:mysql /data/mysqldata/
4:启动
innobackupex --defaults-file=/etc/my.cnf --user=backup --password='bc.123456' --socket=/var/lib/mysql/mysql.sock --slave-info --safe-slave-backup --no-timestamp /backup/full
备份源库上恢复日志
备份完成后,还不能用于恢复,一些未提交的事物需要恢复,需要恢复redo logo的数据,确保数据一致
[root@dg backup]\# innobackupex --apply-log /backup/full
传输数据到新的备库
[root@dg backup]\# scp -r full/ dgt:/backup/
官方参考
https://www.percona.com/doc/percona-xtrabackup/LATEST/installation/yum_repo.html
percona-toolkit //差异
yum install -y http://www.percona.com/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm
yum install percona-xtrabackup-24 -y
innobackupex --user=root --password=cXXX --defaults-file=/etc/my.cnf /data/backup #备份
innobackupex --apply-log /data/backup/ #日志回滚
innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup #备份恢复
在配置文件中加
datadir= /data/backup/
mysql> stop slave; #停止同步
mysql> reset slave; #清除从连接信息
mysql> show slave status\G; #再查看从状态,可以看到IO和SQL线程都为NO
mysql> drop database weibo; #删除weibo库,weibo为测试数据库
此时,从库现在和新装的一样,继续前进!
正式步骤开始:
1. 主库使用xtrabackup备份
innobackupex --user=root --password=123 ./
生成一个以时间为命名的备份目录:2018-06-19_16-11-01
2. 把备份目录拷贝到从库上
3. 从库上把MySQL服务停掉,删除datadir目录,
sudo rm -rf/var/lib/mysql/
innobackupex --apply-log /data/backup/ #日志回滚
innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup #备份恢复
sudo chown mysql.mysql-R /var/lib/mysql
sudo /etc/init.d/mysql start
#查看已经正常启动
4. 在主库创建test_tb2表,模拟数据库新增数据
mysql> create tabletest_tb2(id int,name varchar(30));
5. 从备份目录中xtrabackup_info文件获取到binlog和pos位置
cat/var/lib/mysql/xtrabackup_info
binlog_pos = filename'mysql-bin.000001', position 429 #这个位置
6. 从库设置从这个日志点同步,并启动
mysql> change masterto master_host='192.168.18.212',
-> master_user='sync',
-> master_password='sync',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=429;
mysql> start slave;
mysql> show slavestatus\G;
***************************1. row ***************************
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
7. 从库查看weibo库里面的表
可以看到IO和SQL线程均为YES,说明主从配置成功。
mysql> show tables;
+---------------------------+
| Tables_in_weibo |
+---------------------------+
| test_tb |
| test_tb2 |
发现刚才模拟创建的test_tb2表已经同步过来。
#################简化####################################################
innobackupex --user=root --password=cXXX --defaults-file=/etc/my.cnf /data/backup #备份
innobackupex --apply-log /data/backup/ #日志回滚
在配置文件中加
datadir= path
注意配置文件中的path 和/data/backup 不能相同。
innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup #备份恢复
主从都开启了gtid,在设置从库的时候遇到了问题
mysql> CHANGE MASTER TO MASTER_HOST=‘xxx’,MASTER_USER='replicant',MASTER_PASSWORD=‘xxx’, MASTER_LOG_FILE='bin.000050', MASTER_LOG_POS=191;ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
解决的办法
mysql> change master to master_auto_position=0;
Query OK, 0 rows affected (0.34 sec)
mysql> CHANGE MASTER TO MASTER_HOST=‘xxx’,MASTER_USER='replicant',MASTER_PASSWORD=‘xxx’, MASTER_LOG_FILE='bin.000050', MASTER_LOG_POS=191;
Query OK, 0 rows affected, 2 warnings (0.51 sec)
mysql> START SLAVE;
Query OK, 0 rows affected (0.08 sec)
mysql> SHOW SLAVE STATUS \G
change master to master_host='10.21.8.57',master_user='mysqlsync',master_password='12345678',MASTER_AUTO_POSITION=1;
备份:
/data/bin/xtrabackup/bin/innobackupex --user=root --password=cXXX --defaults-file=/etc/my.cnf /data/backup/full/
恢复:
1:应用日志
/data/bin/xtrabackup/bin/innobackupex --apply-log /data/backup/2014-01-24_11-36-53/
2:数据恢复
/data/bin/xtrabackup/bin/innobackupex --copy-back --defaults-file=/etc/my.cnf /data/backup/2014-01-24_11-36-53/
3:
chown -R mysql:mysql /data/mysqldata/
4:启动
innobackupex --defaults-file=/etc/my.cnf --user=backup --password='bc.123456' --socket=/var/lib/mysql/mysql.sock --slave-info --safe-slave-backup --no-timestamp /backup/full
备份源库上恢复日志
备份完成后,还不能用于恢复,一些未提交的事物需要恢复,需要恢复redo logo的数据,确保数据一致
[root@dg backup]\# innobackupex --apply-log /backup/full
传输数据到新的备库
[root@dg backup]\# scp -r full/ dgt:/backup/
部分内容来源于网络。